I/O のミスアライメントによるデータベースロギングとは何ですか。
環境
ONTAP OS
回答
NetAppファイラーのパフォーマンスの問題に関しては、ファイラーのパフォーマンスが低下する一般的な原因の1つに、部分的な書き込みがあります。通常、Data ONTAPとWAFLではユーザ書き込み要求を迅速に処理できます。これは、NVRAMへの書き込み後に書き込みが正常に格納されることが保証されるためです。通常、この処理は1ミリ秒未満で完了し、NASおよびSANユーザに高速な書き込みパフォーマンスが提供されます。
これは、書き込み要求が4k WAFLブロック境界で開始され、4kで割り切れるサイズであることを前提としています。この条件を満たさないと、部分的な書き込みが行われます。これには、読み取り、書き込み対象のデータと読み取り対象のデータのマージ、および新しいブロックへの結果の書き込みが含まれます。このプロセスは、本来なら書き込みが中断される可能性がある場所で書き込みを原因に中断させ、処理の処理に時間がかかり、レイテンシが増大します。
部分的な書き込みの一般的な原因は、LUN I/Oのミスアライメントです。ミスアライメントI/Oのインジケータは tats perfstat_lun 、perfstatのセクションの書き込みアライメントヒストグラムにあるLUNです。
OEMメモ
ミスアライメントI/Oの詳細については、KB:「 What is an unaligned I/O?」を参照してください。
この資料では、MS SQL(またはその他のデータベース)のログ書き込みが原因でI/Oのミスアライメントが発生している場合、およびFilerのパフォーマンスへの影響が発生しているかどうかを判断する方法について説明します。
このタイプのI/Oは一般に、0以外の複数のバケットに書き込まれる書き込みとみなされ、 write_partial_blocks次のような一定の割合で書き込まれます。
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo.0:0%
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo. 1:4%
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo.2:0%
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo. 3:6%
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo.4:0%
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo. 5:57%
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo. 6:21%
lun:/vol/sql_log/lundggtHJeWTKaT:write_align_histo.7:0%
lun:/vol/sql_log/lundggtHJeWTKaT:read_partial_blocks: 4%
lun:/vol/sql_log/lundggtHJeWTKaT: write_partial_blocks:6%
通常、上記のようなヒストグラムはLUNのアライメントが正しくないと誤って解釈されますが、LUNタイプをさらに調査すると、LUNがホストアプリケーションに適したタイプであることがわかります。実際、上記のパターンはデータベースログアプリケーションで一般的です。この場合、MS SQL Serverトランザクションログについて説明しますが、これらのプリンシパルは他のデータベースアプリケーションや他のワークロードにも適用される可能性があります。
この記事では、このような状況でよく発生する質問を回答します。
「LUNのタイプが適切で、ホスト側での適切なアライメントが確保されている場合、このLUNにミスアライメントI/Oがあるのはなぜですか?」
この例では、Windows 2008サーバが考慮されます。NetApp LUNタイプはwindows_2008である必要があります。 デフォルトで開始オフセットが修正され、NTFSではシステムバッファキャッシュが使用されるため、このLUNに作成されたNTFSファイルシステムへのI/Oは自動的にアライメントされ、書き込み処理が4Kで割り切れるようになります。
では、NTFSが適切にアライメントされた書き込みを保証している場合、このNTFSパーティション原因にSQL ServerがロギングするI/Oは、どのようにしてミスアライメントされるのでしょうか。
回答は、Windows CreateFile関数は、 FILE_FLAG_NO_BUFFERING ファイルの読み取りまたは書き込み時にこのシステムキャッシュを無効にするフラグを提供します。現在利用可能なバージョンのSQL Serverではこのフラグが使用されており、書き込みのアライメントがずれてしまう可能性があるため、アライメントの問題に必ずしも注意を払う必要はありません。このフラグの詳細については、Microsoftの ファイルバッファリングに関する記事を参照してください。
SQL Serverトランザクション・ロギングはミスアライメントI/Oを生成するように見えますが、必ずしもFilerのパフォーマンスに大きな影響を与えるわけではありません。次の図の例では、SQLログのバッチで構成される512KのSANブロックの書き込みが含まれています。
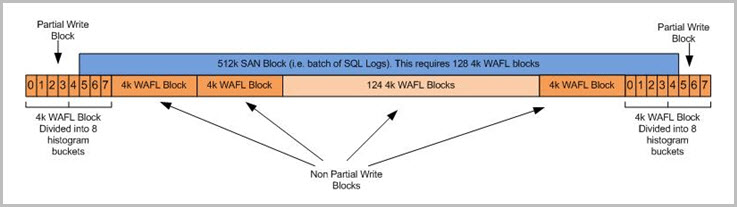
注:A512k SAN書き込みでは128個の4K WAFLブロックが消費されます。前述の処理(1つ目のWAFLブロックのバケット5で開始)でWAFLブロックの中央からミスアライメントに到達した場合、その処理はミスアライメントされているとみなされ、 write_align_histo.5 (バケット5)にこの処理が表示されます。また、この要求の処理に使用される最初と最後のWAFLブロックは部分書き込みになります。ただし、この2つの部分ブロックについては、126個の非部分ブロックがあるため、このシナリオでの影響は最小限です。
書き込みアライメントのヒストグラムを評価する場合は、LUNの平均処理サイズを考慮する必要があります。上記のシナリオに基づいて、処理サイズを大きくすると、小さい処理サイズよりも影響が少なくなります。
Filerに実際にどの程度の影響があるかを確認するには、wafl_susp –wから次の統計を確認します。
pw.over_limitは、wp.partial_writeカウントがを超えたときの発生回数ですpartial_write_limit。partial_write_limit以前は50に修正されていましたが、新しいバージョンのData ONTAPではプラットフォームに依存しています。WAFL_WRITEは、wafl_writeイテレーション中にFilerが受信した新規メッセージの実際の数です。
pw.over_limit と wafl_write 新しいメッセージの関係は絶対的なものではありませんが、一般的には、 pw.over_limit 新しい WAFL_WRITE メッセージに対するの比率を計算することで影響を判断できます。
例:
pw.over_limit = 90145
WAFL_WRITE (from â??New Messagesâ?? section) = 603444
90145 / 603444\xa0= .15 or 15%
この場合、単にデータをNVRAMに書き込む場合と比較して、データをマージして書き込みを完了するために、新しいWAFL書き込み100件につき約15件のブロックを同期的に読み取る必要があります。WAFLは書き込み確認応答をブロックせずに非同期的に少数の部分書き込みを処理しますが、WAFLが50を超える部分書き込みを未処理にすると、これらの処理を同期的に処理し始めます。これにより、書き込みの完了に必要な時間が大幅に増加します。これらの書き込みは pw.over_limit カウンタに反映されます。上記の割合が高いほど、パフォーマンスに影響を与える可能性が高くなります。原因のパフォーマンスへの影響に対するパーセンテージの高さは、いくつかの要因に依存するため、 pw.over_limit/wafl_write 'ハイウォーターマークを 宣言することはできません。
追加情報
AdditionalInformation_text