Cassandra 修復 progress slow アラートと Frequent Cassandra - Reaper サービスの再起動 StorageGRID 11.4 の場合
- Views:
- 54
- Visibility:
- Public
- Votes:
- 0
- Category:
- storagegrid-webscale<a>Cassandra</a><a>StorageGRID 11.4</a><a>CassandrapairProgressSlow</a>
- Specialty:
- sgrid
- Last Updated:
環境
- NetApp StorageGRID 11.4 ( 11.2.0.3 より前)
- 新しい StorageGRID 環境
- NetApp StorageGRID 環境を 11.3 からアップグレード( 11.3.0.11 以前のホットフィックス)
問題
- StorageGRID 11.4 を新規に導入した後、または 11.3.0.11 より前のリリース(例 11.3.0.10 またはその他のビルド 11.3 )から 11.4 にアップグレードした後、ユーザは StorageGRID GUI で次のアラートを受け取ることがあります。
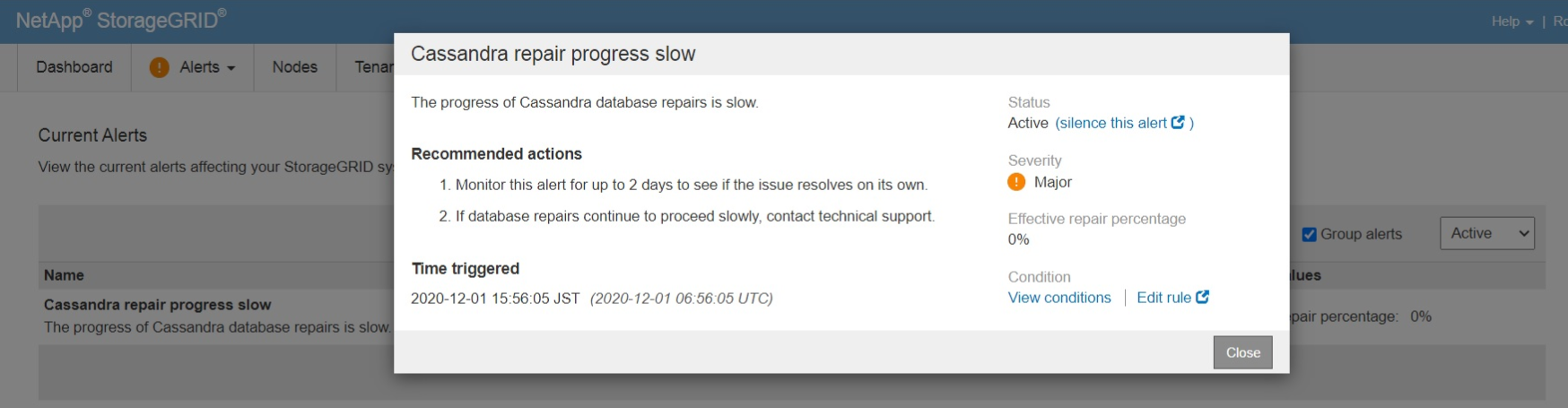
Cassandra repair progress slowは、サービスの利用不可や通信の問題など、多くの問題が原因である可能性があります。- この記事に一致する問題を確認するために、いくつかの追加の署名を確認できます。
Cassandra repair progress slowこのアラートは 2 日間にわたって有効な修復率が 0% で保持されています。- Cassandra 修復処理を実行する Cassandra - REaper サービスは、さまざまなストレージノードで頻繁に再起動します。
これは /var/local/log/servermanager.log ストレージノード上のファイルで確認できます。
| cassandra-reaper | restart initiated
| cassandra-reaper | cassandra-reaper ended
| reaper | starting reaper
/var/local/log/cassandra-reaper.loglumberjack コレクションに含まれているかの下の Cassandra リーパーログreaper.logに整合性レベルまたはQUORUMEACH_QUORUM:
WARN [storagegrid:615635d0-342b-11eb-b6cc-4bacd6a2d5fe:615c9e91-342b-11eb-b6cc-4bacd6a2d5fe] 2020-12-08 18:57:38,140 i.c.s.SegmentRunner - Failed to connect to a coordinator node for segment 615c9e91-342b-11eb-b6cc-4bacd6a2d5fe
com.datastax.driver.core.exceptions.UnavailableException: Not enough replicas available for query at consistency EACH_QUORUM (2 required but only 0 alive)
- ストレージ
reaper_commands.txtノードの lumberjack 収集に含まれるかspreaper --reaper-host=localhost --reaper-port=9403 status-cluster storagegrid、ストレージノードに対する SSH セッションでこのコマンドを実行すると、一部またはすべてのキースペースの修復に最後のイベントに対する次のメッセージが含まれていることが Cassandra REaper の修復リストに示されます。
"creation_time": "2020-11-24T23:05:08Z",
"current_time": "2020-12-08T18:59:39Z",
"datacenters": [],
"duration": "7 days 0 hours 2 minutes 13 seconds",
"end_time": "2020-12-01T23:07:22Z",
"estimated_time_of_arrival": null,
"id": "7f8d00b0-2ea9-11eb-b76b-d7a5b22a5393",
"incremental_repair": false,
"intensity": 1.000,
"keyspace_name": "storagegrid",
"last_event": "Postponed a segment because no coordinator was reachable",
"nodes": [],
"owner": "auto-scheduling",
"pause_time": null,
"repair_parallelism": "PARALLEL",
"repair_thread_count": 4,
"repair_unit_id": "dc8dbfa0-17c7-11eb-b890-676ddd59fc8a",
"segments_repaired": 0,
"start_time": "2020-11-24T23:05:08Z",
"state": "ABORTED",
"creation_time": "2020-11-17T20:50:58Z",
"current_time": "2020-12-08T18:59:40Z",
"datacenters": [],
"duration": "7 days 0 hours 0 minutes 32 seconds",
"end_time": "2020-11-24T20:51:31Z",
"estimated_time_of_arrival": null,
"id": "9882a450-2916-11eb-8180-07cae1e33f50",
"incremental_repair": false,
"intensity": 1.000,
"keyspace_name": "reaper_db",
"last_event": "Postponed a segment because no coordinator was reachable",
"nodes": [],
"owner": "auto-scheduling",
"pause_time": null,
"repair_parallelism": "PARALLEL",
"repair_thread_count": 4,
"repair_unit_id": "dc818aa0-17c7-11eb-b890-676ddd59fc8a",
"segments_repaired": 0,
"start_time": "2020-11-17T20:50:59Z",
"state": "ABORTED",