Active IQ Wellness :最大インパクト-このシステムはパフォーマンス容量の限界に近づいています
すべてのとおり
環境
ONTAP 9
回答
この情報を確認することの価値:
- パフォーマンス容量またはヘッドルームは、ワークロードのパフォーマンスがレイテンシの影響を受ける前にノードまたはアグリゲートに配置できる作業量を測定します。
- 利用可能なパフォーマンス容量を把握して管理することで、ワークロードのプロビジョニングとバランスを行い、予想される応答時間を実現できます。
この健康チェックはどのように検証されますか?
現在のパフォーマンス容量は、次の 3 つの方法でアクセスおよび表示できます。
- ONTAP 9 ドキュメント『 Identifying Remaining Performance Capacity 』で概説されている手順に従ってください
- この方法では、 ONTAP システムに保持されている 1 カ月のヒューリスティックデータが利用されます。
- Active IQ Unified Manager
- この方法では、 Active IQ Unified Manager によって収集された 3 か月のデータを CM_Archive 形式で利用します。

- この方法では、 Active IQ Unified Manager によって収集された 3 か月のデータを CM_Archive 形式で利用します。
- Active IQ
- (ノード CPU ) CPU パフォーマンス容量は、 peak_performance カウンタと current_utilization で異なります。

- (ローカル階層 - アグリゲート利用率) Active IQ にはピーク値がないため、利用可能なパフォーマンス容量にスポットライトを当てることはできません。ただし、現在の利用率の急増は確認できます。
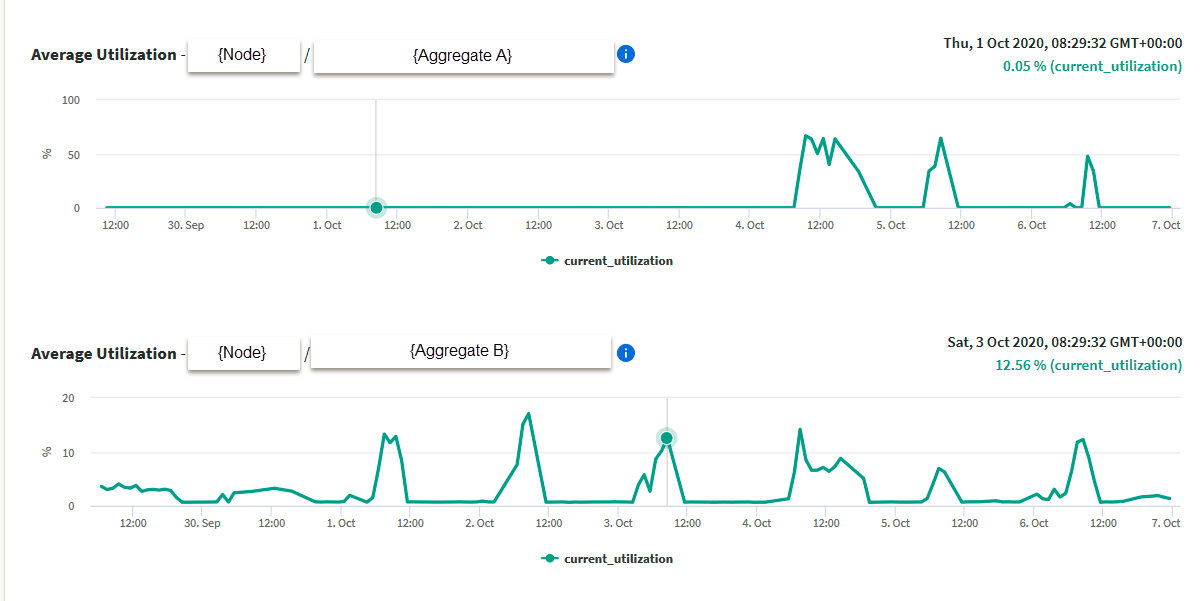
- データアグリゲートがないシステムやバックアップ / ディザスタリカバリの役割を持つシステムでは、ドライブ数が少ないか、または定期的に大量のシーケンシャル I/O が発生するため、アグリゲートの利用率に低パフォーマンスのヘッドルームが確保される可能性があることに注意してください。
- I/O あたりのレイテンシの増加が問題とならないシステムでは、このリスクのインスタンスは無視してかまいません。
- リスクは、日次パフォーマンスデータ通知 AutoSupport メッセージでネットアップに送信される AutoSupport Counter Manager のデータによって検証されます。
- 評価されたデータは、 ONTAP 9 の CLI で 1 カ月分の計算に沿っています。
- 既存のすべての NetApp システムで利用可能なパフォーマンス容量を確認し、このアラートの影響レベルを判断します。
- 99.5 番目のパーセンタイルまたは上位 0.5% より大きい値を指定すると、リスクが高くなります
- 99 から 99.5 パーセンタイルの値は、になります 中リスク
- (ノード CPU ) CPU パフォーマンス容量は、 peak_performance カウンタと current_utilization で異なります。
このアクティブな IQ ウェルネスルールで提供される情報について、どうすればよいですか?
- このアクティブな IQ の事前警告の計画がすでにある場合は、アクティブな IQ ダッシュボードで確認します。
- これにより、健康に関する警告が表示されても、対処する計画がない問題であることが保証されます。
- このタイプのシナリオに対処するには、次の手順を実行
- 使用可能なパフォーマンス容量が不十分で処理できない場合は、ワークロードを増やしないでください。現在のワークロードではレイテンシの増加に耐えられません。
- パフォーマンスへの影響が発生した時点に対応して計画できるように、スループット( xBPS/IOPS/ )や使用率などのワークロードインジケータを監視していることを確認します。
まず、パフォーマンス管理ガイダンスをご[1]紹介します。このガイダンスには、 Active IQ Unified Manager の使用、しきい値の設定、アラートの設定が含まれます。
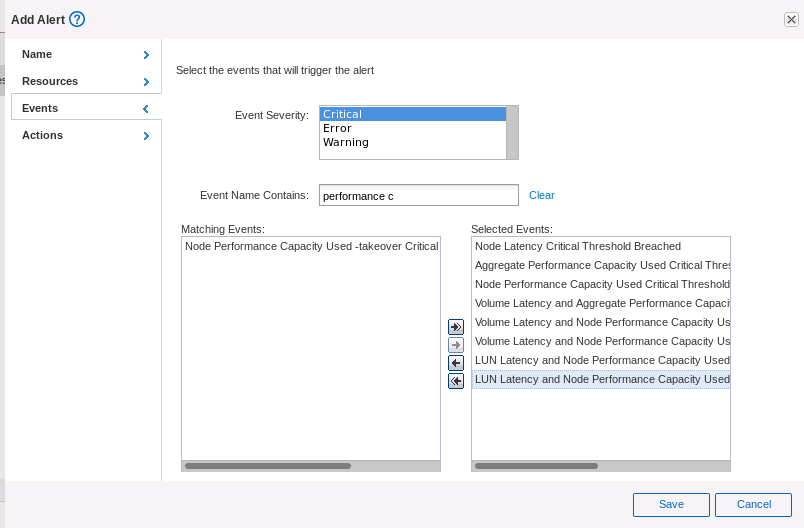
次のカウンタを監視できます。
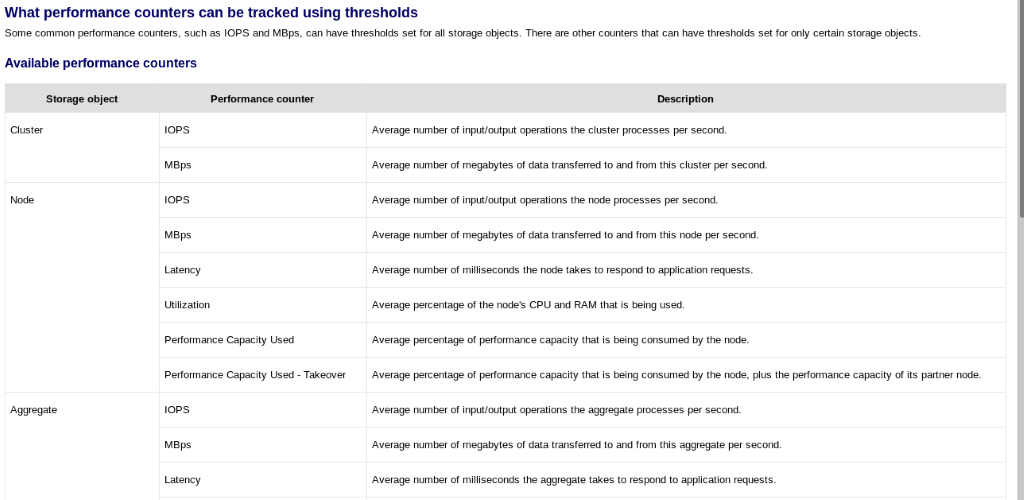
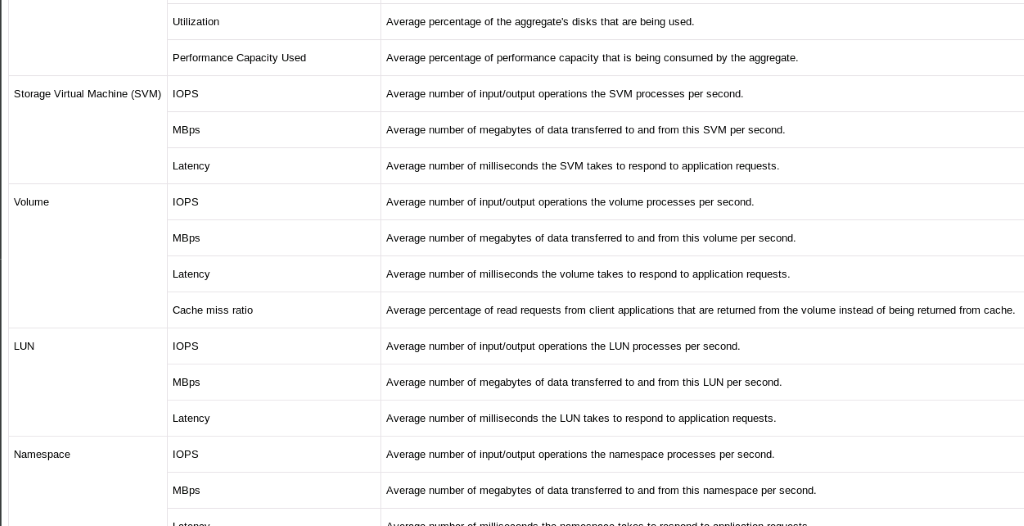
- 選択したしきい値を監視しているときに、必要に応じて容量のしきい値を超過したことに関する警告を検出し、ワークロードを低負荷ノードに減らしたり、再配置したりして、期待どおりのパフォーマンスを維持します。
- Unified Manager の使用状況の概要パネルを使用して、最も消費量の多いワークロードを特定し、それらのワークロードが同じコントローラを共有しないようにします。
- Active IQ を使用して、現在とピーク時のパフォーマンス( CPU )の差や、 AutoSupport から提供されるパフォーマンス容量情報に関連する平均利用率( aggr )の急増を確認します。
現在の利用率が最大パフォーマンスや急増している場合は、ワークロードを確認し、問題がある場合は負荷の低いノードにワークロードを再配置することを推奨します。 - KB :監視ツールを使用してパフォーマンスの問題を修正する方法を確認します
追加情報
このトピックの詳細情報はどこで入手できますか?